2. Syntax¶
2.1. Terminology¶
a=b+c;
2.2. Backus Naur Form (BNF)¶
<syntactic category> ::= a string of terminals and nonterminals
2.2.1. BNF Examples¶
<primitive-type> ::= boolean
<primitive-type> ::= char
<primitive-type> ::= boolean | char | byte | short | int | long | float | ...
<argument-list> ::= <expression> | <argument-list> , <expression>
<selection-statement> ::=
if ( <expression> ) <statement> |
if ( <expression> ) <statement> else <statement> |
switch ( <expression> ) <block>
<method-declaration> ::=
<modifiers> <type-specifier> <method declarator> <throws-clause> <method-body> |
<modifiers> <type-specifier> <method-declarator> <method-body> |
<type-specifier> <method-declarator> <throws-clause> <method-body> |
<type-specifier> <method-declarator> <method-body>
2.2.2. Extended BNF (EBNF)¶
- item? or [item] means the item is optional.
- item* or {item} means zero or more occurrences of an item are allowable.
- item+ means one or more occurrences of an item are allowable.
- Parentheses may be used for grouping
2.3. Context-Free Grammars¶
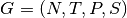
where
is a set of symbols called nonterminals or syntactic categories.
is a set of symbols called terminals or tokens.
is a set of productions of the form
where
and
is a special nonterminal called the start symbol of the grammar.
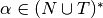
2.3.1. The Infix Expression Grammar¶
A context-free grammar for infix expressions can be specified as
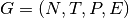 where
where
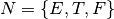
 is defined by the set of productions
is defined by the set of productions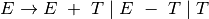
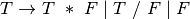
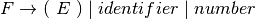
2.4. Derivations¶
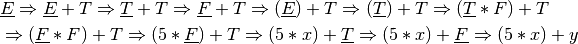
2.4.2. Types of Derivations¶
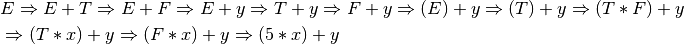
Practice 2.2
Construct a right-most derivation for the expression x*y+z.
2.4.3. Prefix Expressions¶
2.4.4. The Prefix Expression Grammar¶
A context-free grammar for prefix expressions can be specified as
where
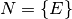
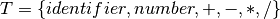 is defined by the set of productions
is defined by the set of productions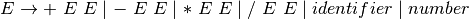
Practice 2.3
Construct a left-most derivation for the prefix expression +4*-a b x.
2.5. Parse Trees¶
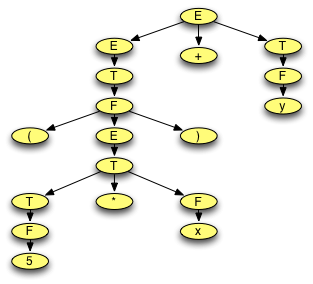
Fig 2.1 A Parse Tree
Practice 2.4
What does the parse tree look like for the right-most derivation of (5*x)+y?
Practice 2.5
Construct a parse tree for the infix expression 4+(a-b)*x.
HINT: What has higher precedence, “+” or “*”? The given grammar automatically makes “*” have higher precedence. Try it the other way and see why!
Practice 2.6
Construct a parse tree for the prefix expression +4*-a b x.
2.6. Abstract Syntax Trees¶
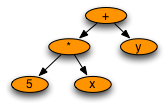
Fig 2.2 An AST
Practice 2.7
Construct an abstract syntax tree for the expression 4+(a-b)*x.
2.7. Lexical Analysis¶
2.7.1. The Language of Regular Expressions¶
The language of regular expression is defined by a context-free grammar. The context-free grammar for regular expressions is 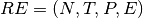 where
where
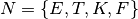
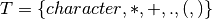 is defined by the set of productions
is defined by the set of productions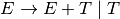
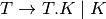
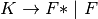
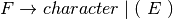
letter.letter* + digit.digit* + ‘+’ + ‘-‘ + ‘*’ + ‘/’ + ‘(‘ + ‘)’
Practice 2.8
Define a regular expression so that negative and non-negative integers can both be specified as tokens of the infix expression language.
2.7.2. Finite State Machines¶
Formally a finite state automata is defined as follows.
- where
(pronounced sigma) is the input alphabet (the characters understood by the machine),
is a set of states,
is a subset of
,
is a special state called the start state, and
(pronounced delta) is a function that takes as input an alphabet symbol and a state and returns a new state. This is usually written as
.
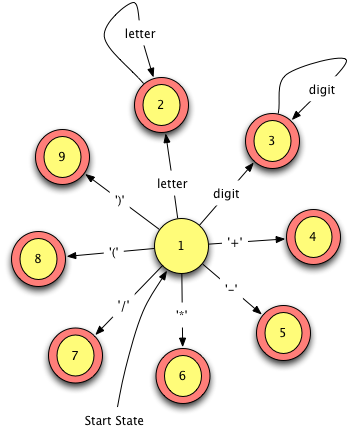
Fig 2.3 A Finite State Machine
2.7.3. Lexer Generators¶
2.8. Parsing¶
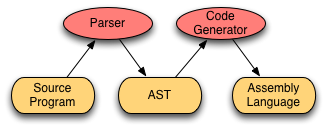
Fig 2.4 Parser Data Flow
2.9. Top-Down Parsers¶
2.9.1. An LL(1) Grammar¶
The grammar for prefix expressions is LL(1). Examine the prefix expression grammar where
is defined by the set of productions2.9.2. A Non-LL(1) Grammar¶
Some grammars are not LL(1). The grammar for infix expressions is not LL(1). Examine the infix expression grammar where
is defined by the set of productions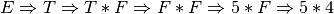
2.9.3. An LL(1) Infix Expression Grammar¶
The following grammar is an LL(1) grammar for infix expressions. where
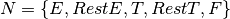 is defined by the set of productions
is defined by the set of productions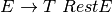
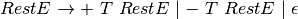
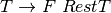
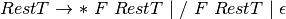
Practice 2.9
Construct a left-most derivation for the infix expression 4+(a-b)*x using the grammar in An LL(1) Infix Expression Grammar, proving that this infix expression is in L(G) for the given grammar.
2.10. Bottom-Up Parsers¶
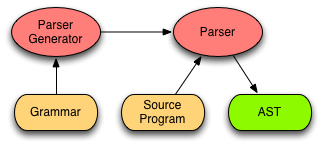
Fig 2.5 Parser Generator Data Flow
2.10.1. PDA¶
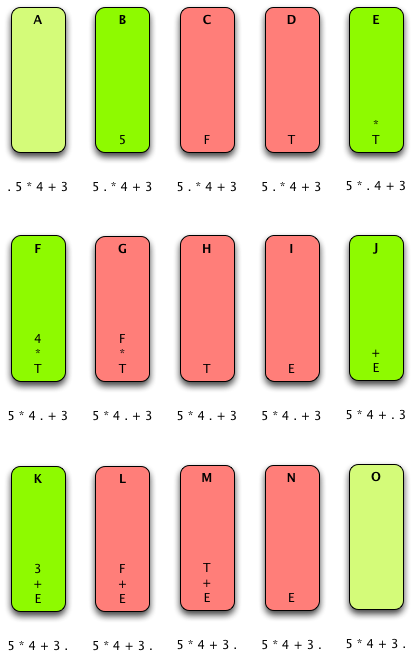
Fig 2.6 A Pushdown Automaton Stack
2.10.2. Parsing an Infix Expression¶
Consider the grammar for infix expressions as
where
is defined by the set of productions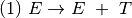
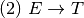
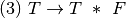
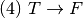
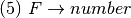
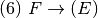
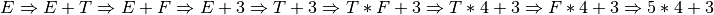
Practice 2.10
For each step in PDA, is there a shift or reduce operation being performed? If it is a reduce operation, then what production is being reduced? If it is a shift operation, what token is being shifted onto the stack?
Practice 2.11
Consider the expression (6+5)*4. What are the contents of the pushdown automaton’s stack as the expression is parsed using a bottom-up parser? Show the stack after each shift and each reduce operation.
2.11. Ambiguity in Grammars¶
if a<b then
if b<c then
writeln("a<c")
else
writeln("?")
<statement> ::= if <expression> then <statement> else <statement>
| if <expression> then <statement>
| writeln ( <expression> )
2.12. Other Forms of Grammars¶
2.13. Limitations of Syntactic Definitions¶
2.14. Chapter Summary¶
2.15. Review Questions¶
- What does the word syntax refer to? How does it differ from semantics?
- What is a token?
- What is a nonterminal?
- What does BNF stand for? What is its purpose?
- What kind of derivation does a top-down parser construct?
- What is another name for a top-down parser?
- What does the abstract syntax tree for 3*(4+5) look like for infix expressions?
- What is the prefix equivalent of the infix expression 3*(4+5)? What does the prefix expression’s abstract syntax tree look like?
- What is the difference between lex and yacc?
- Why aren’t all context-free grammars good for top-down parsing?
- What kind of machine is needed to implement a bottom-up parser?
- What is a context-sensitive issue in a language? Give an example in Java.
- What do the terms shift and reduce apply to?
2.16. Exercises¶
- Rewrite the BNF in BNF Examples using EBNF.
- Given the grammar in The Infix Expression Grammar, derive the sentence 3*(4+5) using a right-most derivation.
- Draw a parse tree for the sentence 3*(4+5).
- Describe how you might evaluate the abstract syntax tree of an expression to get a result? Write out your algorithm in English that describes how this might be done.
- Write a regular expression to describe identifier tokens which must start with a letter and then can be followed by any number of letters, digits, or underscores.
- Draw a finite state machine that would accept identifier tokens as specified in the previous exercise.
- For the expression 3*(4+5) show the sequence of shift and reduce operations using the grammar in Parsing an Infix Expression. Be sure to say what is shifted and which rule is being used to reduce at each step. See the solution to practice problem 2.11 for the proper way to write the solution to this problem.
- Construct a left-most derivation of 3*(4+5) using the grammar in An LL(1) Infix Expression Grammar.
2.17. Solutions to Practice Problems¶
These are solutions to the practice problems. You should only consult these answers after you have tried each of them for yourself first. Practice problems are meant to help reinforce the material you have just read so make use of them.
2.17.1. Solution to Practice Problem 2.1¶
This is a left-most derivation of the expression. There are other derivations that would be correct as well.
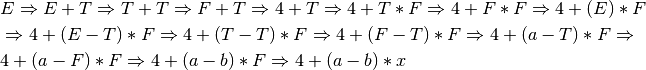
2.17.2. Solution to Practice Problem 2.2¶
This is a right-most derivation of the expression x*y+z. There is only one correct right-most derivation.
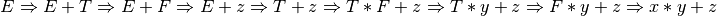
2.17.3. Solution to Practice Problem 2.3¶
This is a left-most derivation of the expression +4*-a b x.
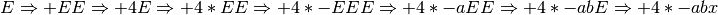
2.17.4. Solution to Practice Problem 2.4¶
Exactly like the parse tree for any other derivation of (5*x)+y. There is only one parse tree for the expression given this grammar.
2.17.5. Solution to Practice Problem 2.5¶
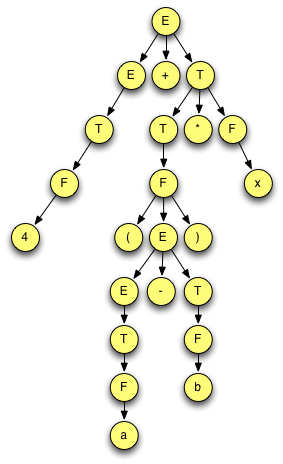
Fig 2.7 The parse tree for practice problem 2.5
2.17.6. Solution to Practice Problem 2.6¶
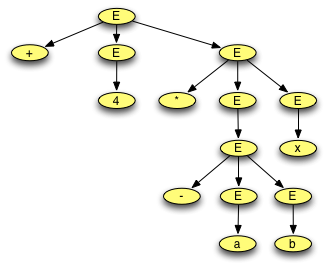
Fig 2.8 The parse tree for practice problem 2.6
2.17.7. Solution to Practice Problem 2.7¶
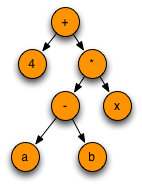
Fig 2.9 The abstract syntax tree for practice problem 2.7
2.17.8. Solution to Practice Problem 2.8¶
In order to define both negative and positive numbers, we can use the choice operator.
letter.letter* + digit.digit* + ‘-‘.digit.digit* ‘+’ + ‘-‘ + ‘*’ + ‘/’ + ‘(‘ + ‘)’
2.17.9. Solution to Practice Problem 2.9¶
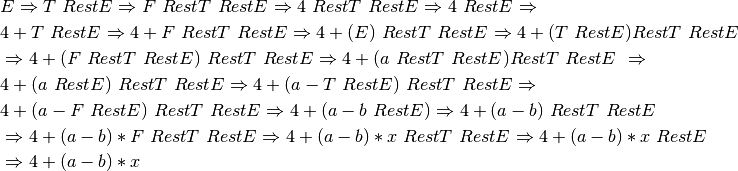
2.17.10. Solution to Practice Problem 2.10¶
In the parsing of 5*4+3 the following shift and reduce operations: step A initial condition, step B shift, step C reduce by rule 5, step D reduce by rule 4, step E shift, step F shift, step G reduce by rule 5, step H reduce by rule 3, step I reduce by rule 2, step J shift, step K shift, step L reduce by rule 5, step M reduce by rule 4, step N reduce by rule 1, step O finished parsing with dot on right side and E on top of stack so pop and complete with success.
2.17.11. Solution to Practice Problem 2.11¶
To complete this problem it is best to do a right-most derivation of (6+5)*4 first. Once that derivation is complete, you go through the derivation backwards. The difference in each step of the derivation tells you whether you shift or reduce. Here is the result.
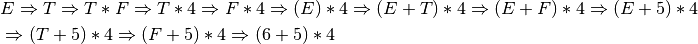
We get the following operations from this. Stack contents have the top on the right up to the dot. Everything after the dot has not been read yet. We shift when we must move through the tokens to get to the next place we are reducing. Each step in the reverse derivation provides the reduce operations. Since there are seven tokens there should be seven shift operations.
- Initially: . ( 6 + 5 ) * 4
- Shift: ( . 6 + 5 ) * 4
- Shift: ( 6 . + 5 ) * 4
- Reduce by rule 5: ( F . + 5 ) * 4
- Reduce by rule 4: ( T . + 5 ) * 4
- Reduce by rule 2: ( E . + 5 ) * 4
- Shift: ( E + . 5 ) * 4
- Shift: ( E + 5 . ) * 4
- Reduce by rule 5: ( E + F . ) * 4
- Reduce by rule 4: ( E + T . ) * 4
- Shift: ( E + T ) . * 4
- Reduce by rule 1: ( E ) . * 4
- Reduce by rule 6: F . * 4
- Reduce by rule 4: T . * 4
- Shift: T * . 4
- Shift: T * 4 .
- Reduce by rule 5: T * F .
- Reduce by rule 3: T .
- Reduce by rule 2: E .